Datenmodell des Digitalen Wissensspeichers
Allgemeines
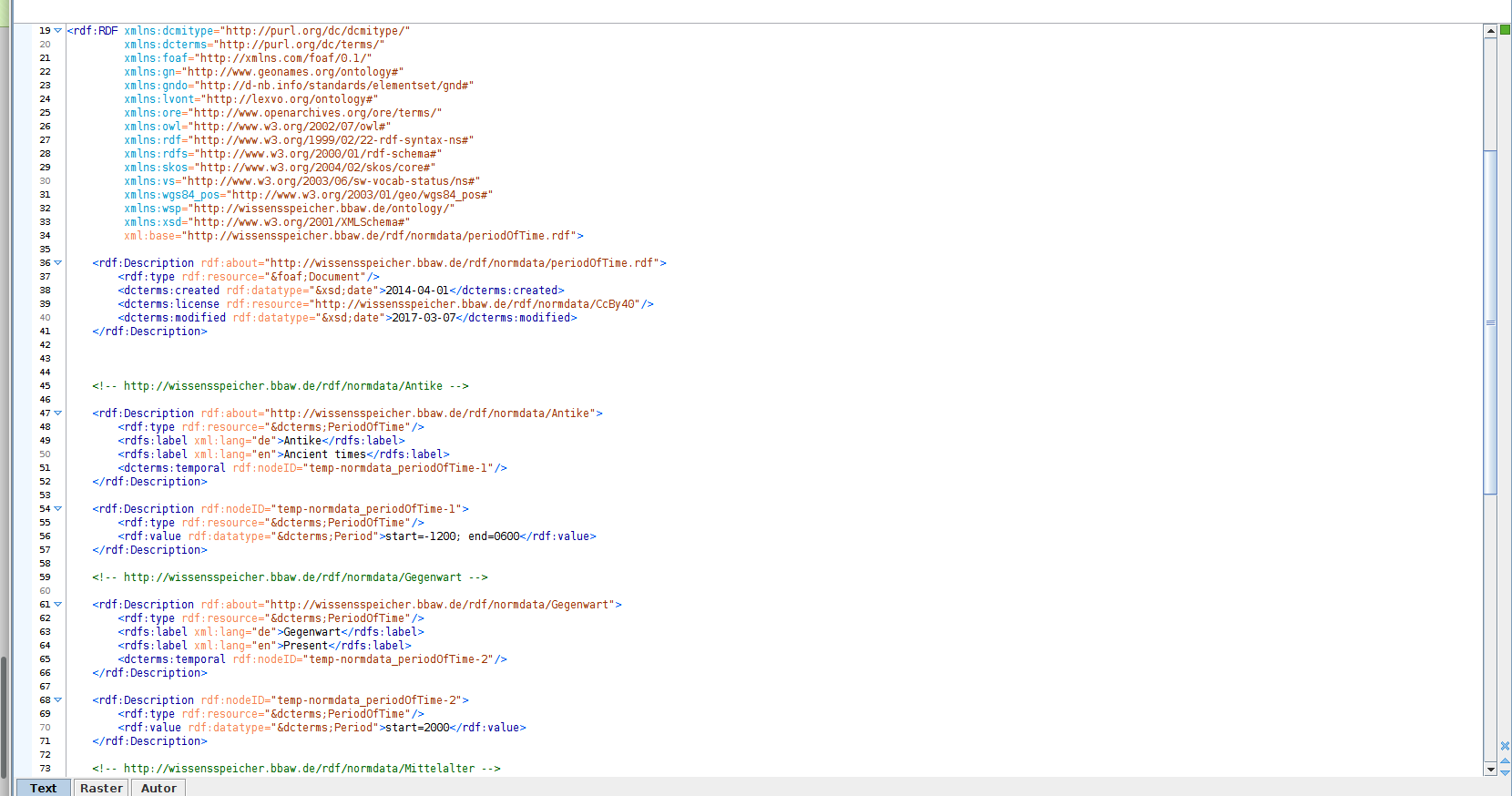
Das Datenmodell des Digitalen Wissensspeichers basiert auf dem von dem World Wide Web Consortium (W3C) empfohlenen Metadatenstandard, dem Resource Description Framework (RDF). Der Standard gehört zu den Semantic Web-Technologien, ist eine Komponente des Semantic Web Layer Cakes und für den Digitalen Wissensspeicher wichtiger Bestandteil für die Schaffung einer diziplinübergreifenden Forschungsinfrastruktur. RDF bedient sich einer einfachen menschenlesbaren Syntax mit Subjekt - Prädikat - Objekt (Tripeln) und ist gleichzeitig maschinenlesbar. Das Datenmodell ist durch die formale Sematik des RDF-Standard graphenbasiert. Alle Digitalen Ressourcen des Digitalen Wissensspeichers erhalten einen eindeutigen Identifier (URI).
Das Datenmodell des Digitalen Wissensspeichers wurde seit Beginn der Projektlaufzeit im Jahre 2012 entwickelt und verbessert. Mit dem Datenmodell werden die Akademievorhaben, Interdisziplinären Arbeitsgruppen, Initiativen und Drittmittelprojekte der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) mit ihren Sammlungen und Webressourcen beschrieben und abgebildet. Das Datenmodell ist sehr flexibel und fordert wenige obligatorische Angaben. Die Beschreibungstiefe kann beliebig auf die vorhandenen Informationen angepasst werden, so dass jedes Projekt der BBAW und andere, externe digitale geisteswissenschaftliche Projekte im Digitalen Wissensspeicher aufgenommen werden können.
Ontologie
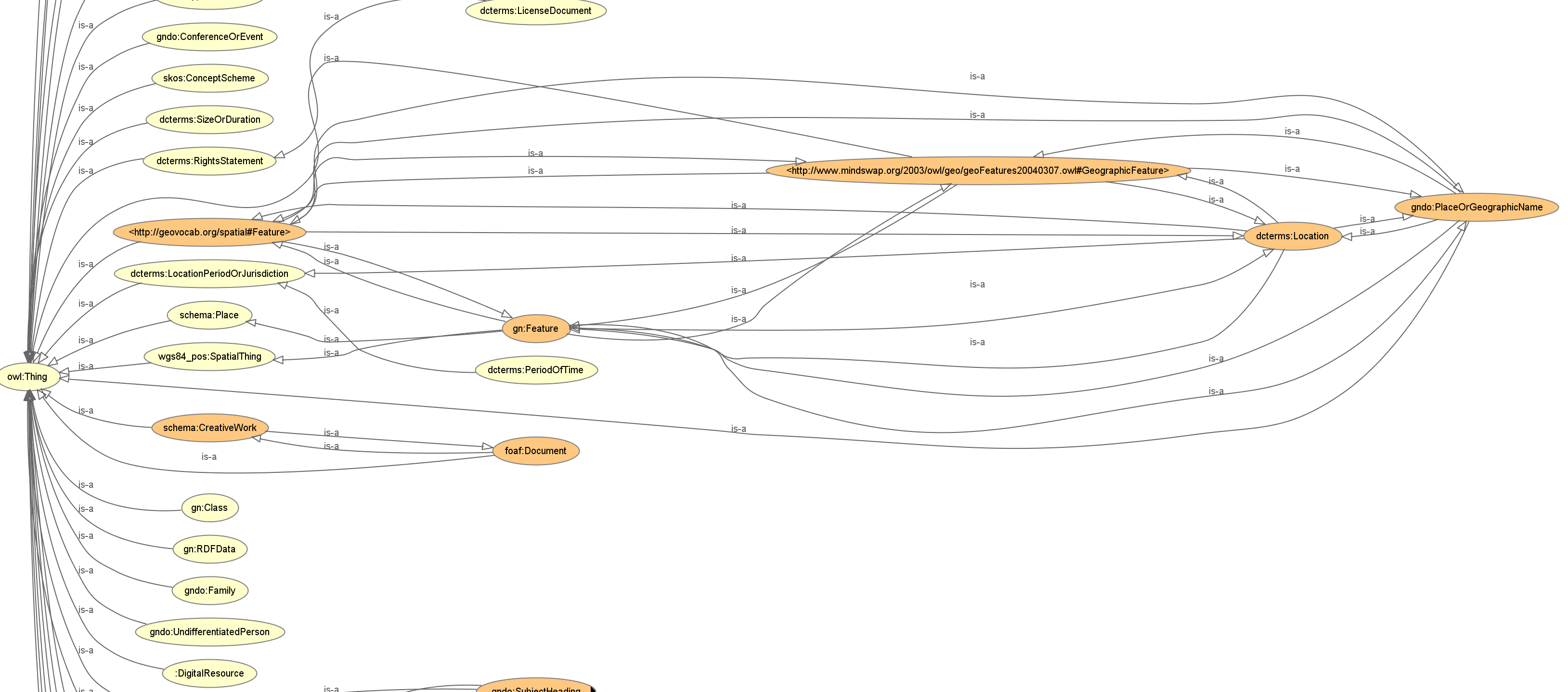
Das Datenmodell des Digitalen Wissensspeichers ist in der Ontologie mit der Web Ontology Language (OWL) und dem RDF-Schema beschrieben. Eine Ontologie bildet das Wissen einer Domäne ab und wird zur Wissenspräsentation verwendet. Sie ist im Zusammenhang mit dem Semantic Web ein mächtiges Instrument, welches das Wissen einer Domäne repräsentieren kann. Alle Klassen, Eigenschaften und Datentypen sind formal in der Ontologie definiert. Sie gibt Information darüber, wie die Konzepte und deren Beziehung zueinander gebraucht und diese in der Community beschrieben und kommuniziert werden. In der Regel werden keine Klassen oder Eigenschaften, die nicht in der Wissensspeicher Ontologie beschrieben sind, verwendet. Benutzen Projekte bereits eigene Klassen und Eigenschaften, werden diese versucht auf das Datenmodell zu mappen oder zu integrieren. Zwei Klassen (wsp:Project und wsp:DigitalResource) gehören zum WSP-Namensraum.
Das übrige Vokabular wurde aus verschiedenen Quellen importiert. Zur Harmonisierung der verschiedenen Fremdvokabulare für den WSP war an wenigen Stellen eine Erweiterung der Originaldefinitionen erforderlich. Diese Stellen sind entsprechend durch Kommentare gekennzeichnet. Für alle Entitätstypen im WSP, sowohl im Bereich der Normdaten als auch für die Projektdaten sind Eigenschaften festgelegt, die entweder obligatorisch oder optional für die jeweiligen Entitäten zu verwenden sind. Pflichtfelder stellen sicher, dass je nach Festlegung für jede Ressourcenbeschreibung ein Basismetadatensatz existiert, der alle Grundinformationen enthält, die eine fehlerfreie Verwendung bzw. Weiterverarbeitung der Metadaten sicherstellt. In der Dokumentation der Metadatenstruktur geben die Eintragungen zur Kardinalität Auskunft über die erforderliche und optionale Verwendung von Eigenschaften.
Konzepte und Definitionen
Im Wissensspeicher wird intern formal zwischen Projektdaten mit Sammlungsdaten und Normdaten unterschieden.
Projektdaten
Zu den Projektdaten zählen alle Metadaten, die Projekte oder Organisationen mit ihren Datensammlungen und Digitalen Ressourcen beschreiben. Die bisher vorhandenen Daten wurden manuell in RDF/XML angelegt und ausgezeichnet. Alle Projektdaten werden pro Projekt in einer separaten RDF-Datei, der Projektdatei, gespeichert, die zur Vereinfachung das Projektkürzel als Dateinamen verwendet. Bei der Überführung der Metadaten in den Tripelstore bleibt diese Datenkapselung mithilfe von benannten Graphen erhalten. Neben den genannten Entitätstypen enthält jede Projektdatei zusätzlich eine Ressourcenbeschreibung der Klasse „foaf:Document“, die Metadaten wie Erstellungs-, Änderungsdatum und Lizenzinformationen der Projektdatei.
Inhaltlich zu Projekten
Projekte und Organisationen werden gemäß ihrer ursprünglichen semantischen Bedeutung verwendet. Projekte sind z.B. Forschungsprojekte wie Vorhaben und Drittmittelprojekte, oder Initiativen und Arbeitsgruppen. Zu Organisationen zählen akademische und nichtakademische Einrichtungen, Organisationen, etc. oder auch Teile von Einrichtungen wie Fachbereiche.
Sammlungen
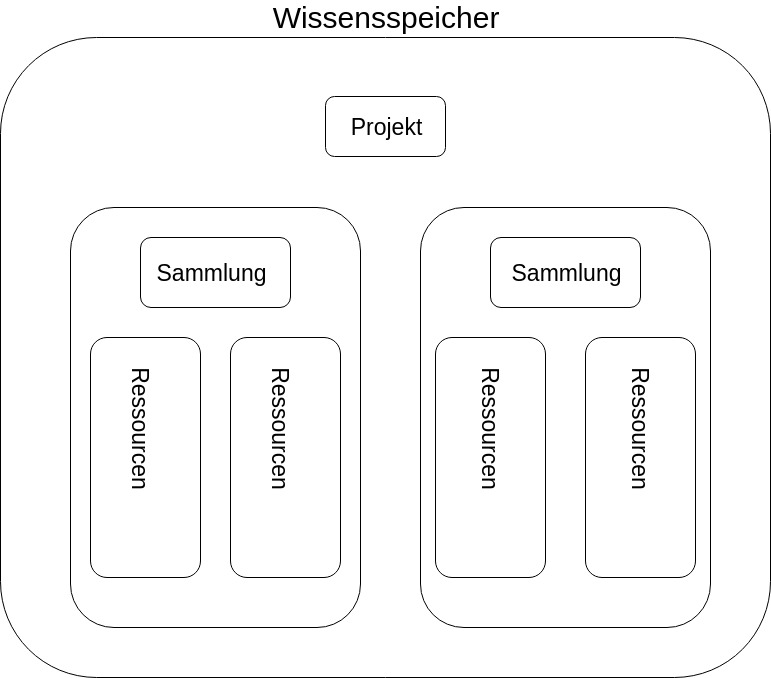
Datensammlungen (Aggregationen) dienen im WSP der Zuordnung einzelner Digitaler Ressourcen zu Gruppen, so dass sich mithilfe von Datensammlungen, Homepages und digitalen Produkten wie Editionen, Wörterbücher, Schriftenreihen oder Datenbanken aber auch Produktteile wie einzelne Briefe einer Briefedition oder auch weniger spezifische Bündelungen von Digitalen Ressourcen beschreiben lassen. Datensammlungen dienen ganz allgemein dazu Gruppierungen von Digitalen Ressourcen abzubilden. Sammlungen werden Projekten zugeordnet und können Untersammlungen und/oder Digitale Ressourcen enthalten. In der Regel enthalten Sammlungen Digitale Ressourcen, welche Entitäten sind, die Einzelressourcen beschreiben wie HTML-Seiten, PDF-Dokumente oder XML-Dateien, die im WSP indexiert werden. Digitale Ressourcen sind Sammlungen zugeordnet und enthalten auf der Beschreibungsebene keine untergeordneten Digitalen Ressourcen.
Normdaten
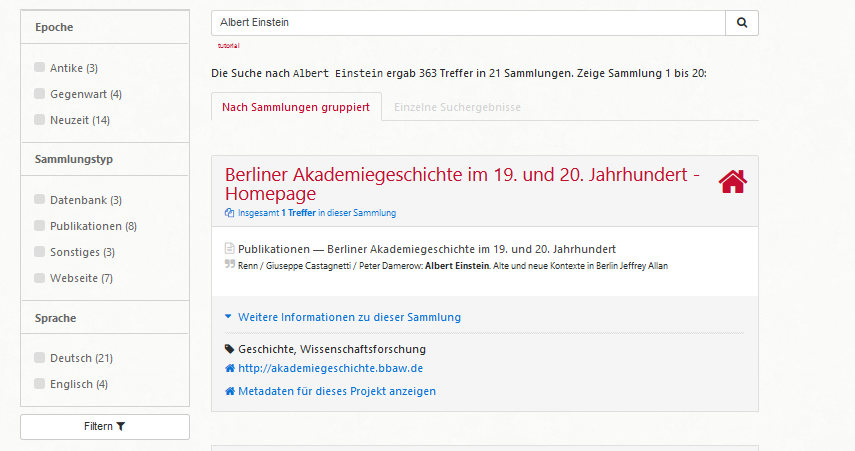
Zu den Normdaten zählen alle Entitäten bzw. Ressourcenbeschreibungen, die als Objekte in den Projektdaten referenziert werden. Wenn Normdaten als Objekte verwendet werden bleiben sie in dieser Datei unbeschrieben. Dazu gehören beispielsweise Personen, die als Projektbeteiligte genannt werden oder auch Projekte, deren Inhalte nicht indexiert werden, die aber in Beziehung zu indexierten Projekten stehen.
Externe Namensräume
Der Digitale Wissensspeicher bedient sich bereits veröffentlichter Ontologien im Bereich des Semantic Webs.
Externe Normdaten
Zu den Normdaten zählen alle Entitäten bzw. Ressourcenbeschreibungen, die als Objekte in den Projektdaten referenziert werden. Akzeptierte externe Normdaten für die Anreicherung von Uniform Resource Identifiers sind:
| Parametername | Gegenstand | Erläuterung | Gebrauch im WSP |
|---|---|---|---|
| DBpedia | Allgemein | Uniform Resource Identifier der extrahierten und strukturierten deutschen Wikipedia | keine Klassen und Eigenschaften genutzt |
| GND | Allgemein | Identifikationsnummer verweist auf den Datensatz der GND von der Deutschen Nationalbibliothek | Klassen und Eigenschaften werden verwendet |
| GeoNames | Geographische Angaben | Referenziert auf einen Uniform Resource Identifier, welcher die Webressource eines Ortes oder Landes eindeutig identifiziert | Klassen und Eigenschaften werden verwendet |
| Lexvo.org | Sprachliche Angaben | Referenziert auf einen Uniform Resource Identifier, welcher die Webressource von Sprachangaben in der Sprachcodierung ISO 639-31 eindeutig identifiziert | Klassen und Eigenschaften werden verwendet |

Nicht immer ist es möglich sich externem Vokabular zu bedienen, deshalb definiert der WSP teilweise eigenes Vokabular, das die vorhandenen Daten besser beschreibt. Das Datenmodell hält sämtliche Normdaten und Klassifikationen für eine genaue Beschreibung der Metadaten vor.
- Rollen und Funktionen von Personen und MitarbeiterInnen werden definiert, um den Personen entsprechende Funktionen innerhalb eines Projektes bzw. einer Sammlung zuweisen zu können (wird mit der Klasse
dcterms:AgentClassbeschrieben). - Die Normdatei Sprachen enthält Ressourcenbeschreibungen von Sprachen und Sprachfamilien, die nicht in den Lexvo.org-Daten bzw. im ISO-Standard enthalten sind. Diese Sprachen sind durch die Verwendung des WSP-Namensraums gekennzeichnet (wird mit der Klasse
dcterms:LinguisticSystembeschrieben). - Lizenzen und Nutzungsrechte zur Weiterverwendung der Webressourcen. Lizenzen sind gemäß der Definition von DCTERMS eine spezielle Form von Nutzungsrechten und deshalb von diesen abgeleitet. Sie werden mit der Eigenschaft
dcterms:licenseausgezeichnet und Nutzungsrechte mit "dcterms:rights"(wird mit den Klassendcterms:LicenseDocumentund die für Nutzungsrechtedcterms:RightsStatementbeschrieben).
dcterms:Location beschrieben).Geografika werden zur Verortung genutzt. Hierbei handelt es sich um spezielle Geografika, die nicht bei Geonames aufgeführt sind (wird mit der Klasse
dcterms:Location beschrieben).foaf:Organisation beschrieben). Werden externe Projekte anderer Akademien in den Wissensspeicher integriert, so wird die Klasse wsp:project genutzt.dcterms:PeriodOfTime beschrieben).
foaf:Person beschrieben).Angelegte SKOS-Vokabulare
In Ermangelung passender externer Vokabulare werden folgende selbst angelegte SKOS-Vokabulare verwendet:
- Sachbegriffe, welche speziell für die Akademie Verwendung finden und in keinen Normdaten wie in den GND-Sachbegriffen beschrieben sind, werden eigens angelegt.
- Sammlungsklassifikation mit inhaltlichen Kategorien wird ohne spezielle Regel angelegt.
- Sammlungsklassifikation mit formalen Kategorien wird in eine der sechs feststehenden Kategorien eingeteilt.
Die WSP-Normdaten sind kein geschlossenes Vokabular, sondern können je nach Bedarf um weitere Ressourcenbeschreibungen erweitert werden. Die Beschreibung der Lizenzen und Nutzungsrechte werden von jeweiligen Anbietern auf SKOS/RDF formuliert, um diese Beschreibungen weiter nutzen zu können. Hier liegen die Rechte bei den jeweiligen Anbietern.
Die im WSP-Namensraum definierten Vokabulare werden im Rahmen des DFG-Projektes des Digitalen Wissensspeichers veröffentlicht und die eingetragene Lizenz ist aktuell CC BY 4.0.